Das könnte Sie auch interessieren
Wirkungsvolles Planen auf Basis einer genauen Informationsgrundlage
Die Produktionsplanung sorgt durch die zielgerichtete Terminierung von Produktionsaufträgen und Abstimmung der Kapazitäten der Produktionsressourcen dafür, dass eine hohe Termintreue sowie Produktivität des Produktionssystems erzielt wird und dabei die Bestände niedrig gehalten werden. Sie kann jedoch nur dann wirkungsvoll durchgeführt werden, wenn die in den Informationssystemen der PPS bereitgestellten Informationen, die die Eigenschaften der Produktionsressourcen beschreiben, möglichst genau sind. Weichen die tatsächlichen Ist-Daten von den Plan-Daten ab, führt das zu negativen Auswirkungen wie nicht eingehaltene Termine, eine geringere Auslastung der Produktionsressourcen oder wie die nötige Einplanung von Pufferzeiten, die wiederum einen höheren Bestand mit sich bringen.
Gerade die Bestände werden als Reaktion auf ein regelmäßig ungenaues Planungsergebnis schrittweise erhöht. Das führt dann zu stärkeren Planabweichungen, die sich immer weiter negativ auswirken – eine Abwärtsspirale, die der „Fehlerkreis der PPS“ genannt wird. Transparenz über die Prozesse in der Produktion und realistischere Plan-Daten sind entscheidend, um gar nicht erst in solche Situationen zu gelangen.
Aufwendige Abbildung von Produktionsressourcen
Zur informationstechnischen Unterstützung werden in der Produktionsplanung Informationssysteme wie ERP-, ME- und APS-Systeme sowie Materialflusssimulationsmodelle eingesetzt. In diesen PPS-Systemen werden die Produktionsressourcen, auf denen die Vorgänge der Produktionsaufträge eingeplant werden (z. B. Maschinen und Anlagen), mit ihren Eigenschaften wie Rüst- und Bearbeitungszeiten, Fehlerraten sowie Verfügbarkeiten, abgebildet. Die Eigenschaften müssen für ein gutes Planungsergebnis möglichst genau durch die hinterlegten Informationen beschrieben werden. Vorgabewerte, die auf Grundlage von technologischen Vorgaben oder durch Schätzungen von Expert:innen ermittelt werden, weichen häufig von den tatsächlichen Ist-Daten ab. Sinnvoll ist deshalb, die nötigen Informationen durch eine Datenanalyse anhand von erfassten Betriebsdaten zu beschaffen. So lassen sich die Produktionsaufträge realistischer planen.
Ressourcenparameter wie Rüst- und Bearbeitungszeiten, Fehlerraten sowie Verfügbarkeiten können stark streuen, da unterschiedliche Vorgangsvorgaben wie bestimmte Produktmerkmale oder variierende Prozessbedingungen wie die Beschaffenheit der Produktionsressourcen (z. B. Abnutzungserscheinungen) auftreten. Einfach einen Durchschnittswert zu ermitteln würde die Realität also nicht genau abbilden. Einflussgrößen, die für die Planung ermittelt werden können, sollten somit berücksichtigt werden. Die fortschreitende Digitalisierung und das Industrielle Internet der Dinge (IIot) verschaffen hier Möglichkeiten für eine detailliertere Datengrundlage. Wird beispielsweise an der jeweiligen Produktionsressource ein Vorgang rückgemeldet, können unter anderem spezifische Rüstzeiten den Vorgänger- und Nachfolgerprodukten oder Bearbeitungszeiten den Produktmerkmalen zugeordnet werden. Weitere Parameter wie Maschinenzustände und -beschaffenheiten lassen sich mittels Sensoren erfassen und mithilfe von Vernetzungslösungen direkt in der PPS-Software nutzen.
Weil sich Prozessbedingungen im Laufe der Zeit außerdem wandeln können, ist eine kontinuierliche Datenerfassung und -auswertung nötig. Der Aufwand dafür ist entsprechend hoch. Eine automatisierte Informationsermittlung kann helfen, die Aufwände zu verringern.
Automatisierte Informationsermittlung durch maschinelles Lernen
Ein Lösungsansatz, eine solche kontinuierliche Datenanalyse zu automatisieren, ist das maschinelle Lernen. Algorithmen ermitteln dabei aus den erfassten Betriebsdaten die benötigten Informationen und deren Zusammenhänge zu den genannten Einflussgrößen. Überwachte Lernverfahren, die für diesen Zweck angewendet werden, haben sich als verlässliche Methoden erwiesen.
Zunächst wählen Expert:innen auf Basis ihres Wissens aus, welche Zusammenhänge und Daten relevant erscheinen. Der Aufwand nicht benötigte Daten zu erfassen wird so möglichst gering gehalten und die Abbildung von nicht-kausalen Korrelationen kann vermieden werden.
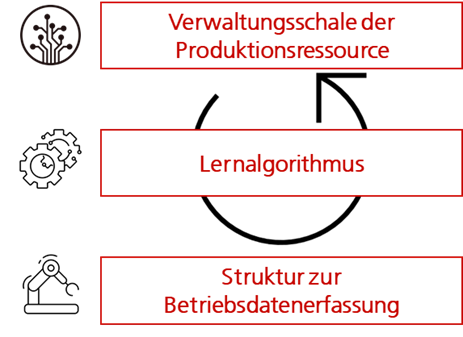
Außerdem ist eine definierte Datenstruktur, die vorgibt, wie die unterschiedlichen Betriebsdaten einheitlich erfasst werden können, Voraussetzung für die Verarbeitung dieser Daten durch einen Lernalgorithmus. Für die Bestimmung der Parameter der Produktionsressourcen bieten sich beispielsweise Entscheidungsbäume als maschinelles Lernverfahren an. Der Entscheidungsbaum bildet für alle auftretenden Kombinationen die aus den Ist-Daten ermittelten Plan-Daten ab (z. B. Produktmerkmal x mit Maschinenzustand y führt zu Plan-Wert z).
Die nötige laufende Anpassung an die sich ändernden Bedingungen kann in einem festen Zyklus durchgeführt werden. Das passiert dann ohne Aufwand automatisch im System.
Informationsbereitstellung durch die Verwaltungsschale
Doch wie können die ermittelten Plan-Daten schließlich im PPS-System genutzt werden? Die sogenannte Verwaltungsschale ermöglicht dem PPS-System, die Plan-Daten über eine vereinheitlichte Schnittstelle abzurufen – so wird Interoperabilität möglich. Die Verwaltungsschale kann als eine schlanke Datenbank verstanden werden, die eine einzelne Produktionsressource beschreibt und von verschiedenen Software-Systemen genutzt werden kann.
Davor sind die Daten durch das maschinelle Lernverfahren schon zu Informationen verarbeitet worden. Ein Beispiel: Ein Sensor an einer Produktionsmaschine misst die Geschwindigkeit der Antriebswelle als Zeitreihe. Diese Werte werden vorverarbeitet zum Beispiel um den Maschinenzustand (läuft/steht) zu erfassen und im nächsten Schritt mithilfe des Algorithmus die Auslastung pro Monat (Verhältnis produktiv zu Stillstand) zu ermitteln. Diese Informationen werden in der Verwaltungsschale strukturiert zur Verfügung gestellt – d. h. mit einer einheitlichen Bezeichnung an einer definierten Stelle – und von verschiedenen Software-Systemen (z. B. MES, ERP-System) genutzt.
Die Möglichkeit, Informationen über die reale Produktionsressource anhand von aktuell erfassten Daten abzubilden, entspricht außerdem der Idee des digitalen Zwillings.
Für die Produktionsplanung ergeben sich mithilfe von maschinellem Lernen und der Verwaltungsschale deutliche Vorteile: Die Informationsgrundlage, anhand der die realistischen Plan-Werte bestimmt werden, ist nicht nur aktuell und detailliert, sondern der Aufwand, um diese Informationen bereitzustellen dabei auch noch verhältnismäßig gering.
Das könnte Sie auch interessieren
© Fraunhofer IGCV
Das könnte Sie auch interessieren
Das könnte Sie auch interessieren
Das könnte Sie auch interessieren
Das könnte Sie auch interessieren
Das könnte Sie auch interessieren
Das Schlagwort „Künstliche Intelligenz“ (KI) ist längst auch im deutschen Mittelstand angekommen: Vom Einsatz von sogenannten Machine-Learning-Modellen wie Random Forest oder Deep-Learning-Modellen wie neuronalen Netzen können nicht nur große Unternehmen wie Amazon, Google oder Zalando profitieren, auch bei KMU gibt es zahlreiche Möglichkeiten. Beispielhaft seien hier Personal-Einsatz-Planung und Optimierung von Produktionsabläufen genannt. Aber auch die Disposition kann mithilfe von KI optimiert werden und so manuellen Bearbeitungsaufwand und Einkaufs- sowie Lagerkosten einsparen. In immer mehr mittelständischen Unternehmen rückt dieses Thema in den Fokus und es werden erste Projekte zur KI-Anwendung für spezifische Use Cases auf den Weg gebracht. Wofür es häufig noch an Bewusstsein fehlt, ist die Bedeutung der Datenbasis.
KI-Modelle müssen „lernen“
Die meisten KI-Modelle sind stark abhängig von der Menge und der Qualität der vorliegenden Daten. Sollen beispielsweise mithilfe von sogenannten rekurrenten neuronalen Netzen zukünftige Absätze prognostiziert werden, ist es nötig, dass eine Datenhistorie vorliegt, also Aufzeichnungen über vergangene Absätze. Diese Art von Daten, bei denen eine zeitliche Abhängigkeit zwischen aufeinanderfolgenden Beobachtungen besteht, nennt man in der Statistik Zeitreihe.
Ein KI-Prognosemodell kann auf vergangenen Absätzen lernen, wie sich diese über die Zeit verändern. Dieses Lernen der Muster und Abhängigkeiten in den Daten nennt man das Trainieren des Modells. Je weniger vergangene Daten vorliegen, desto weniger kann das Modell auch aus der Vergangenheit lernen. Besonders zum Tragen kommt dies bei saisonalen Einflüssen, z. B. wiederkehrenden jährlichen Verläufen. Damit diese aus den Daten erkannt werden können, müssen vollständige Zyklen aufgezeichnet sein. Ein Beispiel: Damit ein Modell rein aus den Daten erkennt, dass beispielsweise Sonnencreme vor allem im Sommer verkauft wird, müssen die Sonnencreme-Verkäufe aus mehreren vergangenen Jahren vorliegen.
Bleiben wir beim Beispiel der Absatzprognose. Um Absätze vorherzusagen, kann es sehr hilfreich sein, zusätzliche Informationen zu den vergangenen Absätzen zu betrachten. Häufig spielen zeitliche Aspekte eine Rolle, wie Wochentage oder die Jahreszeit. Erfahrene Dispositionsmitarbeitende wissen beispielsweise, dass vor dem Schulstart die Verkäufe an Heften und Stiften steigen. Damit das Prognosemodell diesen Zusammenhang ebenfalls lernen kann, muss die Information über den anstehenden Schulstart in den Daten hinterlegt sein, z. B. über eine Monatsangabe. Andere Aspekte können Rabattaktionen oder Werbekampagnen sein, die die Verkäufe ankurbeln. Sind diese nicht in den Vergangenheitsdaten hinterlegt, kann das KI-Modell den Effekt dieser Marketingmittel nicht erkennen und so auch nicht vorhersagen, wie sich die Absätze bei einer zukünftigen Aktion verhalten werden.
Welche Daten sind für mich relevant und wie erhebe ich sie?
Um also die Potenziale von KI voll zu nutzen, ist es sinnvoll, im Vorfeld ein Konzept zur Datenerhebung und -sammlung aufzustellen. Dazu zählt die Analyse, welche Daten für die vorliegende Fragestellung relevant sind, aber auch, wie diese erhoben und so abgespeichert werden können, dass sie für Auswertungen und KI-Anwendungen verwendet werden können. Eventuell werden Marketingkampagnen schon getrackt, allerdings nur mithilfe eines Kalenders oder einer lokal abgelegten Excel-Tabelle. Viel besser ist es, wenn auch diese Daten zentral gespeichert werden, sodass sie zusammen mit den Absatzdaten direkt ausgelesen und zusammengeführt werden können.
Ein entscheidender Faktor dafür ist, dass das ERP-System flexibel genug ist, um an die Bedürfnisse des Unternehmens angepasst zu werden. Dabei spielt es erst einmal keine Rolle, ob es sich um eine eigens programmierte IT-Lösung handelt oder ein ERP-System eines großen Anbieters eingekauft wurde. Wichtig ist nur, dass es für das Unternehmen mit annehmbarem Aufwand möglich ist, zusätzlich Daten zu erfassen und Daten auch unkompliziert zu exportieren. Ebenfalls sollten gewisse Qualitätskriterien klar sein:
- Wie können menschliche Schwächen wie Tippfehler vermieden werden, z. B. durch Automatisierung?
- Gibt es Pflichtfelder, die hinterlegt werden müssen, und optionale, die nur unter bestimmten Umständen relevant sind?
- Werden leere Felder durch Standardwerte gefüllt?
- Können wir auf Konsistenz in den Eingaben prüfen und so frühzeitig Fehler vermeiden?
- Was passiert, wenn Fehler korrigiert werden müssen?
Dabei sollte auch immer der Arbeitsaufwand bzw. die Bedienbarkeit durch Mitarbeitende mitgedacht werden. Felder und Spalten müssen so benannt werden, dass klar ist, welcher Eintrag gefordert ist. Wo möglich sollten Einträge automatisch gefüllt oder Menüs mit Auswahlmöglichkeiten integriert werden. Ist den Mitarbeitenden der Nutzen dieser Daten nicht klar oder bedeutet das Erheben einen großen Mehraufwand in ihrer täglichen Arbeit, droht die Gefahr, dass Einträge fehlerhaft sind oder ganz fehlen. Sind dies nicht nur Ausnahmen, sondern ist ein größerer Anteil der Daten fehlerhaft, wird ein KI-Modell Zusammenhänge fehlerhaft lernen. Die Motivation der Mitarbeitenden spielt also auch für die Datenerhebung eine zentrale Rolle.
Ein Beispiel für diese Gefahr ist das Erfassen von Nein-Verkäufen, also Anfragen von Kunden, welche aufgrund von fehlender Verfügbarkeit nicht bedient werden können. Für Unternehmen ist es eine enorm wichtige Information, wie häufig und unter welchen Umständen eine Kundennachfrage nicht erfüllt werden konnte. Sind Mitarbeitende allerdings nicht ausreichend geschult oder haben sie Angst, dass Nein-Verkäufe für die Bewertung ihrer Arbeit eine negative Rolle spielen könnten, werden diese nicht korrekt erfasst. Eine mögliche Konsequenz ist, dass die Prognose der Kundennachfrage auf Basis der reinen Verkaufszahlen die tatsächliche Nachfrage unterschätzt. So werden auch in Zukunft nicht mehr Artikel auf Lager gelegt und das wahre Umsatzpotenzial wird nicht erreicht.
Grundlage, um verschiedene anfallende Daten im Unternehmen von unterschiedlichen Mitarbeitenden korrekt zu erfassen und für Auswertungen nutzbar zu machen, ist eine Dokumentation des Systems bzw. der Datenstruktur. Das Aufstellen einer detaillierten Dokumentation scheint zunächst einen unnötig hohen Aufwand zu bedeuten. Allerdings lassen sich so langfristig Zeit und Ressourcen sparen. Wissen zum ERP-System und der Datenstruktur ist somit nicht an einzelne Mitarbeitende gebunden. Nicht nur innerhalb des Unternehmens können so die Monitoring- und Analysepotenziale auf Basis der Daten besser genutzt werden, auch für KI-Projekte mit externen Partnern stellt dies einen großen Vorteil dar. So lässt sich der Zeitaufwand in der ersten Phase eines KI-Projekts, in der ein gemeinsames Verständnis der Datenbasis geschaffen werden muss, stark verringern. Außerdem sind so die Informationen gesichert, sodass auch nach Personalwechsel problemlos vorhandene Systeme weiter genutzt werden können.
Das Beispiel Absatzprognose
Gerade wenn es um Prognosefragestellungen geht, sind meistens zwei Arten von Daten interessant:
- zeitabhängige (dynamische) Daten, auch Bewegungsdaten genannt, wie z. B. Absatz- und Auftragsdaten, Feiertage, Ferien, Wochentage, aber auch Wetterdaten oder Rohstoffpreise
- statische Daten (Stammdaten), die sich nicht über die Zeit verändern, aber sich zwischen den Zeitreihen unterscheiden. Beim Absatzprognose-Beispiel können das Eigenschaften sein, wie Artikelgruppenzugehörigkeiten, die Einteilung in Saison- und Nicht-Saisonware, Warenumfang, Gewicht usw.
All diese Daten können als relevante Eingangsdaten einem Modell übergeben werden, um auf dieser Basis die Absätze noch besser prognostizieren zu können als nur mit Blick auf die vergangenen Absätze. Gerade bei Bewegungsdaten ist es also sinnvoll, sich frühzeitig Gedanken zu machen, wie diese aufgezeichnet und abgespeichert werden können.
Eine große Herausforderung bei Prognosen allgemein ist, gute Vorhersagen auch für Fälle zu treffen, in denen noch keine oder nur wenige vergangene Werte vorliegen. Wie prognostiziert man beispielsweise die Absätze eines neu eingeführten Artikels? Eine große Hilfe ist dabei, wenn Informationen zu Ähnlichkeiten zwischen Artikeln vorliegen. Nimmt man eine neue Marke Schrauben ins Sortiment auf, wird sich diese eher verkaufen wie andere Schrauben, d. h. in ähnlichen Mengen und in ähnlicher Häufigkeit, als Wärmepumpen. Sind diese Ähnlichkeiten hinterlegt, z. B. indem jedem Artikel eine Gruppe zugeordnet ist („Schrauben“, „Rohre“, „Fußleisten“, etc.), können die Artikel allein aus den Daten gruppiert werden, ohne dass hier aufwendig das Fachwissen aus dem Unternehmen an die beauftragen KI-Expert:innen durch Workshops, Interviews oder lange Befragungen extrahiert werden muss.
So ist es also möglich, mehrere Prognosemodelle zu trainieren, die jeweils auf eine Gruppe angepasst sind. Das Schrauben-Prognosemodell kann gut die zukünftigen Absätze von Artikeln vorhersagen, die zur Gruppe Schrauben zählen. Und da das Modell auf den Daten von Schrauben trainiert wurde, kann es auch sinnvolle Prognosen für eine neue Schraubenart im Sortiment erstellen.
Eine weitere Möglichkeit, wie sogenannte Hierarchien in den Daten wertvolle Beihilfe leisten können, sind konsistente Prognosen über mehrere Aggregationsebenen. Damit die strategische und die operative Planung zusammenpassen ist es z. B. wichtig, dass sich die Prognosen auf Monatsebene zu den Prognosen auf Jahresebene aufaddieren. Gleichzeitig soll auf keiner Aggregationsebene die Prognose an Genauigkeit verlieren. Ein weiteres Beispiel ist die Aggregation über mehrere Standorte des Unternehmens. Hier sind diejenigen Unternehmen im Vorteil, welche unternehmensweit einheitliche Datenformate etablieren, sodass Daten leicht zusammengeführt werden können.
Fazit – Datenfrage immer mitdenken
Für den Einsatz von KI in KMU gibt es also zwei Möglichkeiten: Entweder ein Use Case wird aus den bereits zur Verfügung stehenden Daten abgeleitet oder aber aus dem angestrebten Use Case entstehen Anforderungen an eine Datenbasis. In beiden Fällen muss die Datenfrage immer mitgedacht werden. Da sich die Performance der meisten KI-Modelle mit der Menge an bereitgestellten Trainingsdaten verbessert, muss dies in der Zeitplanung von KI-Projekten berücksichtigt werden, gerade wenn historische Verlaufsdaten verwendet werden sollen. Insbesondere bei KMU ist es wichtig, ein passendes Datenkonzept zu erstellen, das mit den vorhandenen Ressourcen umgesetzt werden kann und diejenigen Anwendungsfälle für KI ermöglicht, die dem Unternehmen den größten Vorteil verschaffen. Deshalb sollte dieses Datenkonzept bereits zusammen mit KI-Expert:innen erarbeitet werden.
Sie brauchen Hilfe bei der Erstellung eines Datenkonzepts? Unsere Expert:innen können Sie kostenfrei im Rahmen einer Potenzialanalyse oder eines Projekts unterstützen!
Das könnte Sie auch interessieren
In seinem Vortrag hat Jakob Kasbauer, Wissenschaftlicher Mitarbeiter am Technologie Campus Grafenau den Teilnehmenden ein Forschungsprojekt vorgestellt, bei dem untersucht wurde, wie mithilfe von elektrischen Geräten in einem smarten Haus herausgefunden werden kann, ob die dort lebende Person in einem gesunden Zustand oder hilfsbedürftig ist. Dafür wurden die Daten eines smarten Stromzählers betrachtet, um daraus die elektrischen Geräte und deren Aktivitäten erschließen zu können.
Dr. Roman-David Kulko, auch Wissenschaftlicher Mitarbeiter am Technologie Campus Grafenau hat den Teilnehmenden die Nahinfrarotspektroskopie (NIR-Spektroskopie) näher gebracht. Diese Technologie kann für das Erkennen und Sortieren von Kunststoffabfällen oder für die zerstörungsfreie Ermittlung der Qualität einer Vielzahl von Lebensmitteln eingesetzt werden. Mit einem Spektrometer, also einem Messgerät, kann die Zusammensetzung der Lichtstrahlung in ein Spektrum zerlegt werden.
Abschließend hat Leon Binder, ebenfalls Wissenschaftlicher Mitarbeiter am Technologie Campus Grafenau die Teilnehmenden anhand eines Fallbeispiels aus dem 3D-Druck durch den typischen Ablauf von Datenanalyse-Projekten geführt und ihnen Best Practices und Hilfestellungen an die Hand gegeben. Somit haben die Interessierten viele Anregungen mitnehmen, wofür Data Analytics und KI eingesetzt werden können.




